
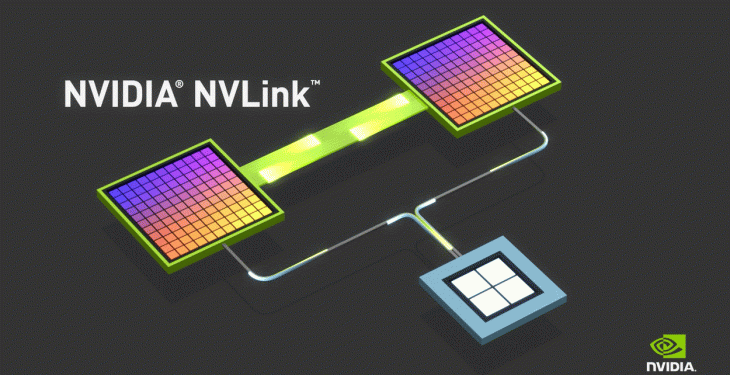
NVLink is a high-speed, direct GPU-to-GPU interconnect developed by NVIDIA, designed to facilitate faster data transfer rates compared to conventional methods. This technology aims to address the limitations of previous interconnect solutions, enabling more efficient data sharing and communication between GPUs. By leveraging NVLink, systems can achieve significantly enhanced performance in data-intensive tasks such as deep learning, scientific computation, and high-performance computing (HPC). The architecture of NVLink not only boosts the bandwidth available for data transmission but also reduces latency, making it a pivotal advancement for multi-GPU configurations in both research and industry applications.view more details about :nvlink speed
What is NVLink and How Does It Work?
Understanding the Evolution of NVLink
The inception of NVLink marked a significant leap in GPU interconnection capabilities, evolving to meet the burgeoning needs of modern computational demands. Initially introduced to overcome the bandwidth and latency limitations inherent in traditional PCIe connections, NVLink has undergone several iterations to enhance data transfer speeds and efficiency. Each version has progressively augmented the bandwidth, starting from a theoretical maximum of 20 GB/s per link in its first generation to more than doubling that capacity in subsequent releases. This evolution caters to the growing requirements of complex computational tasks, including machine learning models and large-scale simulation projects, thereby facilitating a higher degree of parallelism and computational integrity.
Examining GPU Connectivity with NVLink
NVLink’s unique approach to GPU-to-GPU connectivity distinguishes it from other interconnect technologies. By enabling direct communication between GPUs, it eliminates the need for data to traverse through the CPU, significantly reducing data transfer times and minimizing latency. This direct path allows for accelerated data sharing and synchronization across GPUs, essential for scaling applications across multiple GPUs efficiently. This capability is paramount in achieving linear scalability in performance for applications running on multiple GPUs, making NVLink a critical component in the construction of high-performance computing systems and complex neural network models.
Exploring the Role of NVSwitch in NVLink Technology
The NVSwitch technology enhances the capabilities of NVLink by enabling more flexible and scalable configurations of GPU clusters. It acts as a high-speed switch, interconnecting multiple GPUs in a dense configuration without the bandwidth limitations typically associated with PCIe-based systems. NVSwitch facilitates the creation of fully-connected GPU topologies, allowing for equal bandwidth access between any pair of GPUs within a system. This architecture is particularly beneficial in workloads that require intensive peer-to-peer communication, providing a substantial uplift in performance and efficiency in data processing tasks. NVSwitch is a critical enabler for building the next generation of AI supercomputers, offering unparalleled connectivity and data transfer capabilities critical for advanced research and development in AI, deep learning, and high-performance computing domains.
recommend reading: What is NVIDIA NVLink
NVLink Generations: A Deep Dive
Comparing NVLink 1.0, 2.0, and 3.0
NVLink, since its inception, has undergone several upgrades, each aimed at substantially increasing data transfer speeds and efficiency in compute-intensive environments. NVLink 1.0 laid the groundwork by providing a peer-to-peer data transfer system that significantly surpassed the bandwidth capabilities of traditional PCIe connections. NVLink 2.0 built upon this by doubling the data transfer rate, enabling more complex and data-intensive applications to benefit from reduced latency and increased throughput. NVLink 3.0 further refined this technology, enhancing the bandwidth and introducing more sophisticated error correction mechanisms to ensure data integrity in high-performance computing tasks.
The Innovations of NVLink 4.0
NVLink 4.0 represents the latest advancement in this technology, pushing the boundaries of data transfer capabilities even further. It introduces significant improvements in bandwidth and efficiency, catering to the demands of next-generation computing applications, including AI and deep learning. One of the hallmark features of NVLink 4.0 is its compatibility with newer, more powerful GPUs, facilitating even faster data transfers and processing capabilities. This evolution ensures that NVLink remains at the forefront of technology, enabling cutting-edge research and development across various scientific and industrial domains.
Benefits of NVSwitch Chip in Enhancing NVLink Speed
The introduction of the NVSwitch chip has been a game-changer in further enhancing the NVLink technology. By acting as a high-speed switch, NVSwitch enables a more flexible and scalable configuration of GPU clusters. It addresses the bandwidth limitations encountered with previous interconnect technologies, such as PCIe, by facilitating fully-connected GPU topologies. This architecture not only ensures equal bandwidth access between any pair of GPUs within a system but also significantly boosts the overall system performance. The NVSwitch chip thus plays a crucial role in optimizing data transfer speeds, making it an invaluable component in the construction of high-performance computing systems and advanced AI models.
NVLink in Data Centers and High-Speed Networks
Utilizing NVLink for AI and GPU Accelerated Computing Enhancing Bandwidth with Bi-Directional NVLink Connections
In the realm of AI and GPU-accelerated computing, NVLink 4.0 has emerged as a pivotal technology, markedly enhancing the bandwidth and efficiency of data transfer. This improvement is notably realized through the implementation of bi-directional NVLink connections, which enable simultaneous data flow in both directions between GPUs. This architectural advancement significantly reduces latency and increases data throughput, which is essential for the intricate computations carried out in deep learning and AI algorithms. By allowing more data to be processed in parallel and at faster rates, NVLink 4.0 facilitates the development of more sophisticated and complex AI models. Thus, the integration of bi-directional NVLink connections stands as a critical enabler for pushing the boundaries of what is possible in AI research and GPU-accelerated computing, optimizing performance in a diverse range of applications from virtual reality simulations to climate modeling.
NVLink Performance and Applications
Exploring the DGX H100 and NVLink Integration
Maximizing GPU Architecture Efficiency with NVLink
The introduction of the DGX H100 system marks a significant milestone in the application of NVLink technology, showcasing its pivotal role in maximizing GPU architecture efficiency. This cutting-edge system integrates NVLink to enhance the communication speed between its GPUs, thereby optimizing computational performance for high-demand applications such as machine learning and data analytics. The DGX H100, equipped with NVIDIA’s latest H100 Tensor Core GPUs, utilizes NVLink to facilitate higher bandwidth and lower latency connections, enabling more efficient data sharing and processing across GPUs. This integration not only accelerates the computational tasks but also significantly improves the scalability of complex AI and deep learning models. The ability of NVLink to support high-speed interconnects is critical in environments where data and compute requirements are continually expanding, making the DGX H100 a prime example of how next-generation connectivity can drive advancements in technology and research.
The Impact of NVLink in Enabling High-Speed Interconnects
NVLink’s impact extends beyond individual computing systems to the broader architecture of data centers and high-speed networks. Its capability to provide high-speed interconnects is essential for the development of distributed computing environments that demand rapid data transfer and synchronization across a wide array of systems. In such environments, NVLink facilitates the seamless exchange of data, allowing for the integration of multiple GPUs into a cohesive, high-performance computing network. This enhanced connectivity is instrumental in tackling the challenges of processing vast datasets and executing complex computational tasks with greater efficiency. By enabling high-speed interconnects, NVLink plays a vital role in advancing the fields of data science, artificial intelligence, and computational research, paving the way for innovations that leverage the full potential of GPU-accelerated computing.





{kind=link}